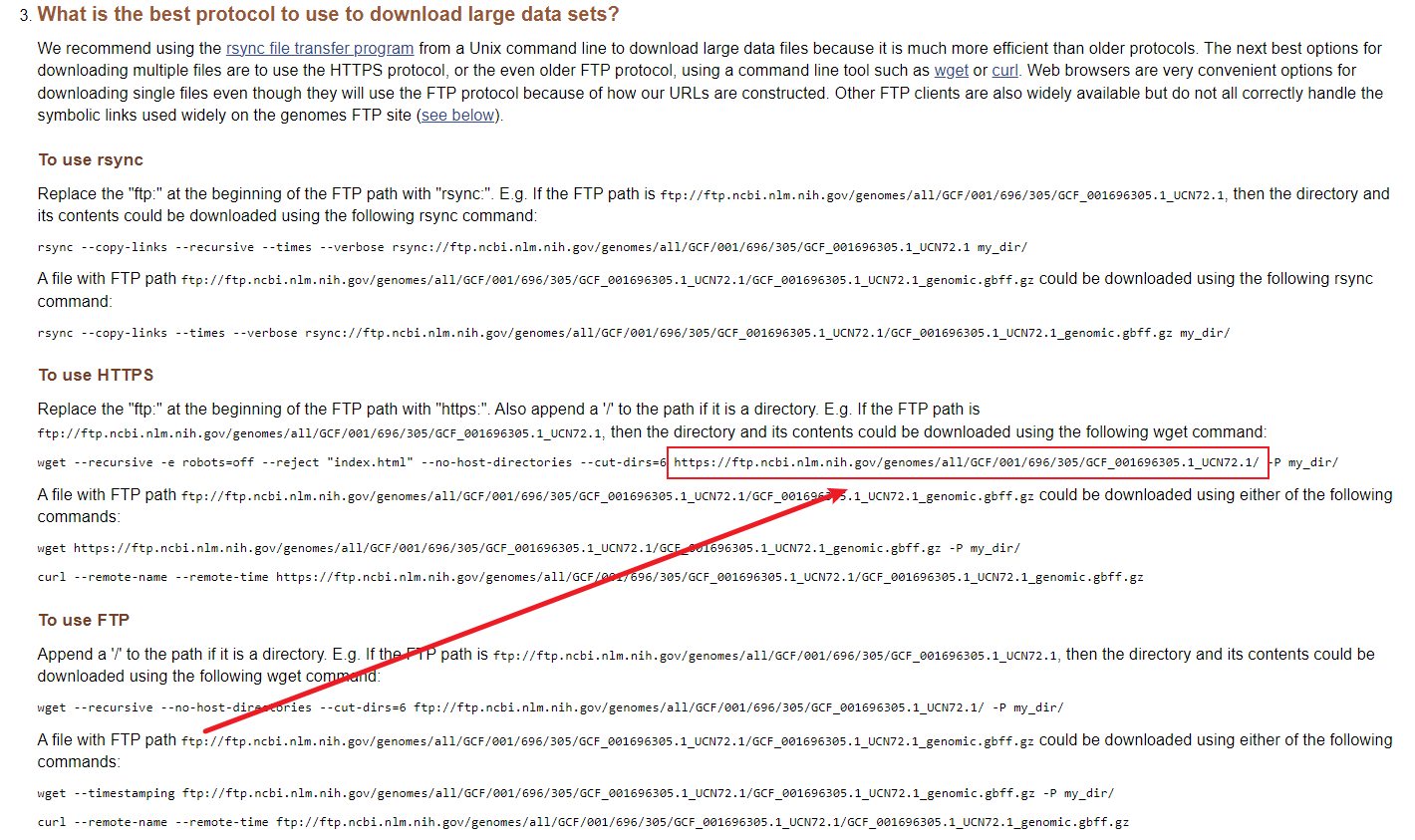
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| df.bins.pan.info %>%
dplyr::select(`Assembly Accession`, `Assembly Name`) %>%
magrittr::set_names(c("acc", "name")) %>%
dplyr::mutate(temp0 = stringr::str_split(acc, "_") %>% sapply("[", 1),
temp1 = stringr::str_split(acc, "_") %>% sapply("[", 2) %>% stringr::str_sub(1,3),
temp2 = stringr::str_split(acc, "_") %>% sapply("[", 2) %>% stringr::str_sub(4,6),
temp3 = stringr::str_split(acc, "_") %>% sapply("[", 2) %>% stringr::str_sub(7,9)) %>%
dplyr::mutate(link = sprintf("https://ftp.ncbi.nlm.nih.gov/genomes/all/%s/%s/%s/%s/%s_%s",temp0, temp1, temp2, temp3, acc, name),
comm = sprintf('wget -np --recursive -e robots=off --reject "index.html" --no-host-directories --cut-dirs=6 %s -P ./',link)) -> down.comm
down.comm %>%
dplyr::select(comm) %>%
write.table(file = "./data/sanqimetagenome/results/分箱/13.泛基因组/基因组下载链接.txt",
col.names = FALSE, row.names = FALSE, quote = FALSE)
|