R语言机器学习框架mlr3学习笔记
mlr3verse基础
mlr3verse其实是个框架,整合了各种机器学习算法。其底层的使用R6语法和data.table数据流;支持并行,可以搭建”图”流学习器。
几点技术说明:
- 使用帮助:?+对象名字,或者对象$help,如learner$help().
- 某些对象不是数据框,as.data.table()转化成数据框再进行查看。
- 超参数调参需要找到原始函数对应的包的函数帮助。
任务类型
- 连续的目标变量:回归
- 离散的目标变量:分类
- 没有目标:聚类和降维等
查看自带的任务:
1 | |
1 | |
创建任务
使用包仔带的数据并创建任务。
1 | |
1 | |
剔除某列
1 | |
1 | |
划分数据
划分数据得到的是行号,并不是直接将数据分成两份。
1 | |
学习器
学习器就是来自不同包里面的算法。
1 | |
1 | |
设定学习器的方法如下:
1 | |
1 | |
开始训练模型
1 | |
1 | |
进行预测
1 | |
模型性能评估
查看性能度量指标:
1 | |
1 | |
1 | |
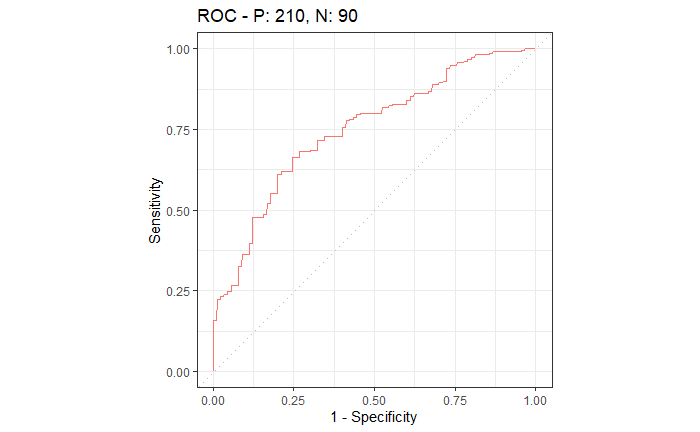
重抽样
1 | |
基准测试
基准测试指的是比较不同的算法、在多个任务或者是不同抽样策略上的平均表现。
测试时要保证测试的公平性,也就是喂给每个算法的数据必须是一样的,也就是重抽样得到的数据应该同时喂给每个算法。
1 | |
图学习器
图学习器的主要用途:
- 特征工程:缺失值插补、特征提取、特征选择、不均衡数据处理……
- 集成学习:装袋法、堆叠法
- 分支训练和分块训练
1 | |
特征工程
加载需要的包
1 | |
什么是特征工程
简单来说就是将自变量转换成能够更好的表达问题本质的新变量的过程,也就是对自变量进行处理。
数据清洗和特征工程属于机器学习中的数据预处理过程,使用mlr3pipelines这个包来实现。
选择器函数
- selector_all(): 选择所有特征
- selector_none():不选择任何特征
- selector_type():根据类型选择特征
- selector_name():根据特征名字选择特征
- selector_grep():利用正则表达式选择特征
- selector_invert():反选某个选择器的特征
- selector_intersect/union/setdiff():两个选择器特征的交集、并集和差集
- selector_missing():选择含有缺失值的特征
- selector_cardinality_greater_than():根据分类特征个数阈值进行筛选
affcet_columns参数
这个参数组要用于说明作用于哪些列。
查看所有的PipeOp
1 | |
1 | |
如何理解
以“标准化”这个管道为例,其中$train()接收训练数据,对输入数据进行标准化处理,在这个过程中训练好的参数(平均值和标准差)将作为state保存下来。在predict()的时候是直接调用state中保存好的参数,而不是重新计算标准差和平均值。
1 | |
缺失值插补
1 | |
1 | |
1 | |
学习器插补
为每个特征变量拟合一个学习器来插补特征。
学习器支持的特征才可以被插补,也就是说回归类型的学习器只能插补整数和数值特征,分类类型的学习器可以插补因子、有序因子和逻辑特征值等。
1 | |
特征缩放
不同特征之间的差异可能会很大,对模型的影响可能会很大,因此需要做归一化处理,也就是对特征进行缩放。
1 | |
特征变换
1 | |
特征降维
1 | |
不均衡数据处理
- 欠采样:多数类只保留了一部分
- 过采样:少数类超量采样
超参数调参
什么是超参数调参
简单来说揪是让模型自动找到最佳参数。
使用mlr3tuning实现。
工作内容
搜索空间、学习器、任务、重新抽样策略、模型性能度量指标及终止条件。
查看学习器超参数
需要先知道学习器包含哪些参数。
1 | |
独立参数
tune()进行超参数调参,需要设定以下参数:
- method:调参方法,支持以下这些
- grid_search:网络搜索
- random_search:随机搜索
- gensa:广义模拟退火
- nloptr:非线性优化
- task:任务
- learner:带调参的学习器或普通学习器
- resampling:重抽样策略
- measures:模型性能评估指标,可以是多个
- search_space:如果是普通的学习器则需要指定搜索空间
- term_evals/term_time/terminator:终止条件,允许评估次数/允许调参时间多少秒/终止器对象
- store_models:是否保存每次的模型
- allow_hotstart:是否允许热启动预拟合模型
- resolution:网格分辨率,网格搜索的配套参数
- batch_size:批量大小,每批次放几组参数配置,以加快运算速度
1 | |
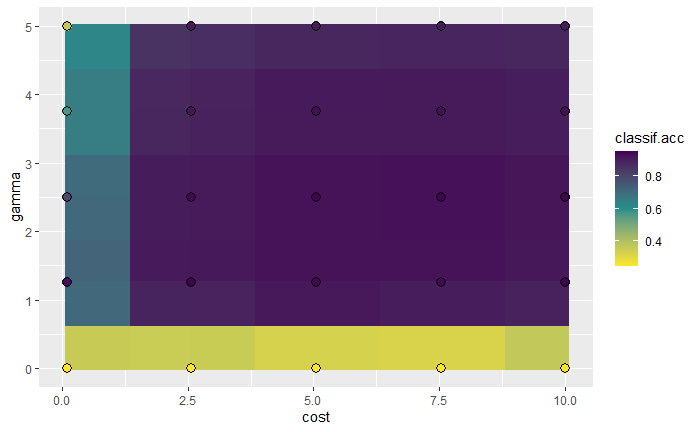
自动调参器
自动调参器
独立调参的缺点:
- 最优参数需要手动更新
- 不方便实现嵌套重抽样
自动调参将超参数和学习器封装到一起,实现自动调参过程,并可以像其他的学习器一样使用。
1 | |
正则化回归
加载需要的包
1 | |
为什么使用正则化回归
多元线性回归时,部分变量之间存在多重共线性,剔除某个变量后回归系数会变化很大,得到的回归模型是“伪回归”,这时候就需要岭回归、Lasso回归或者是弹性网回归,这些方法都是基于一种正则化技术,可以减少过拟合。
岭回归
岭回归是一种改良后的最小二乘法,通过放弃最小二乘法的无偏性,损失部分信息、降低部分精度为代价,得到更符合实际、更可靠的回归方法。
需要注意的是岭回归中自变量的量纲对模型的影响非常大,因此需要对自变量进行标准化,保证所有自变量都是一个量纲上。
岭回归的最佳系数是通过梯度下降法优化得到的。
Lasso回归
Lasso回归和岭回归的差异在于惩罚项不同。
弹性网回归
弹性网回归是岭回归和Lasso回归的整合。
mlr3案例
mlr3调用glmnet包实现正则化回归。有两个学习器:
- regr.glmnet:调用glmnet::glmnet()
- regr.cv_glmnet:调用glmnet::cv.glmnet
两个函数的基本用法为:
1 | |
其中:
- x:自变量
- y:因变量
- family:因变量的类型,默认是gaussian,还可以是binomial、poisson、multinomial、cox、mgaussian
- alpha:弹性网混合系数,0为岭回归,1为Lasso回归,介于0和1之间的是弹性网回归
- lambda:惩罚度的超参数
二者的区别在于cv.glmnet已经的带有交叉验证对lambda调参,自动选择最优的lambda.
1 | |
其余两种正则化回归的调参过程类似。
弹性网回归时,超参数调参需要加一个参数:
1 | |
Logistic回归
加载需要的包
1 | |
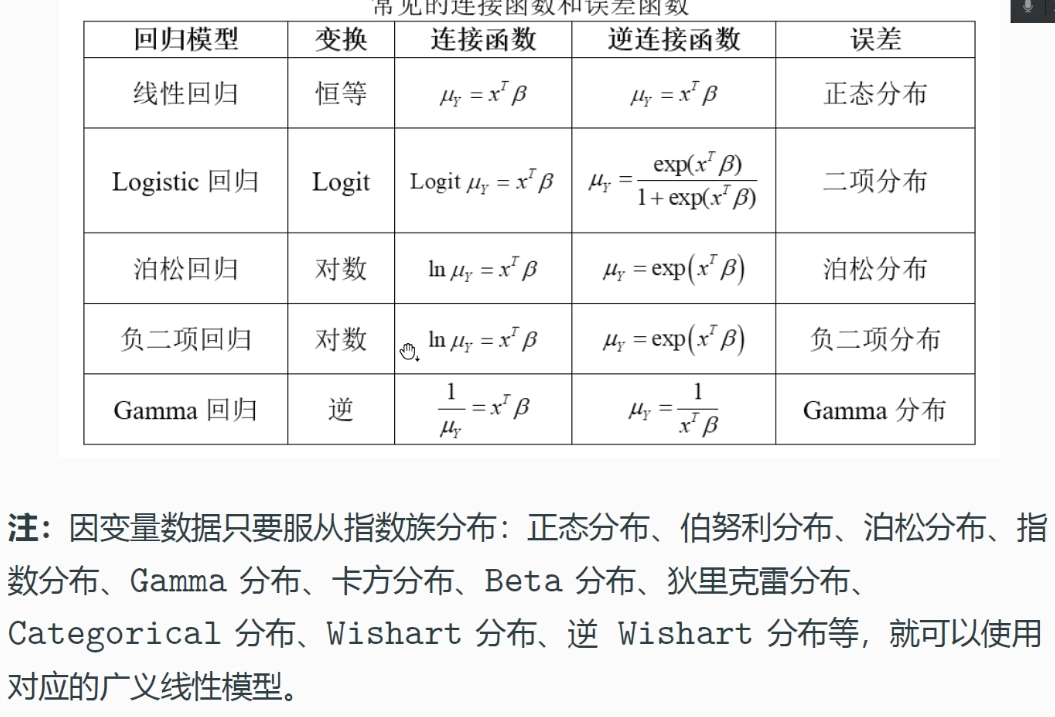
广义线性模型
线性回归要求因变量服从正态分布,但是实际情况下因变量可能是类别型、计数型等,因此需要将线性回归推广到广义线性模型。
广义线性模型相当于一个复合函数,先做线性回归,再接一个变换,变换后得到的就是非正态的因变量数据。

这个过程应该是反过来理解,完成这个变换的函数叫做链接函数。
mlr3案例
1 | |
KNN
加载需要的包
1 | |
如何理解KNN
简单理解为近朱者赤近墨者黑。
KNN和聚类分析的区别在于KNN是有因变量的,聚类分析没有因变量,属于无监督学习。
KNN最重要的参数是K. 距离方法也可以进行超参数调参选择最优的距离计算方法。
常用的距离算法有:
- 欧氏距离:两点之间直线距离的推广,相当于直角三角形的斜边长度。
- 曼哈顿距离:相当于两个直角边的和。
- 余弦相似度:两个向量的余弦夹角。
- 杰卡德相似系数:两个集合交集与并集的元素个数之比。
后面两种方法常用于文本挖掘和推荐算法。
philentropy这个包可以实现46种距离的计算。
如何确定最佳K值
- 交叉验证法:不同的K值进行m折交叉验证。
- 近邻样本加权:如果已知样本距离未知样本距离较远,则需要进行加权处理。
mlr3实例
1 | |
回归的过程类似。
随机森林
加载需要的包
1 | |
关于集成学习
集成学习就是通过构建多个基学习器,按一定的策略结合成强学习器完成学习任务。
装袋法
装袋法采用的是并行机制,基学习器之间没有先后顺序,可以同时进行。装袋法采用的是有放回的抽样方法。
装袋法的代表算法是随机森林。
提升法
提升法采用的是串行机制,基学习器之间存在依赖关系,按顺序进行训练。该算法主要关注降低偏差,每次迭代都关注训练过程中错误的样本,将弱学习器提升为强学习器。
代表算法有AdaBoost、GBDT、XGboost、LightGBM和catBoost等。
堆叠法
堆叠法采用的是分阶段机制,将若干基模型的输出作为输入,再接一层主学习器,得到最终的预测。
随机森林原理
决策树是很弱的分类器,效果一般,但是将多个若学习器通过集成学习技术组合到一起,就可以实现强分类器。
优点
- 不容易过拟合,无需建制
- 可以并行计算,单个决策树可以同时训练
- 可以做分类或者是回归,无需调参,就可以获得很高的分类精度
- 对缺失值和异常值不敏感
- 可以处理很多变量,无需对变量进行约减
缺点
- 树越多越稳定越准确,但是也越慢
- 更擅长分类,回归差一些,回归预测的范围只能在训练数据的范围内
- 结果不容易解释,属于“黑箱”模型
mlr3案例
mlr3实现随机森林调用的是ranger包(要求数据不能有NA)。
1 | |